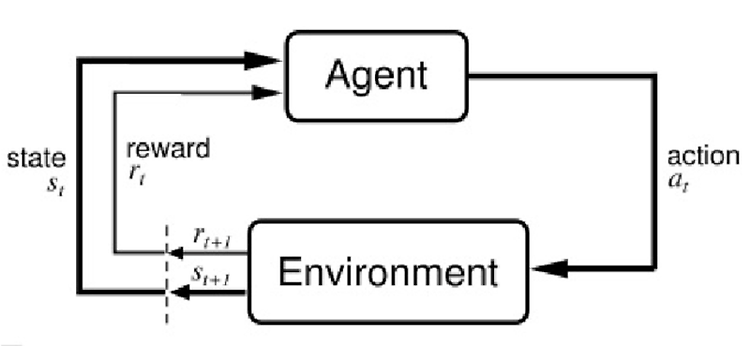
0단계: 재귀적 표현 $v_{\pi}(s_{t})=\mathbb{E}_{\pi}[r_{t+1}+\gamma v_{\pi}(s_{t+1})]$ $q_{\pi}(s_{t},a_{t})=\mathbb{E}_{\pi}[r_{t+1}+\gamma q_{\pi}(s_{t+1},a_{t+1})]$ 1단계: $v_{\pi}$와 $q_{\pi}$를 서로를 이용해 표현 $v_{\pi}(s) = \sum_{a\in A}\pi(a|s)q_{\pi}(s,a)$ $\Leftrightarrow s의 밸류 = \sum_{}(s에서 a를 실행할 확률) * (s에서 a를 실행하는 것의 밸류)$ $q_{\pi}(s,a)=r_{s}^{a}+\gamma \sum_{s'\in S}P_{ss'}^{a}v_{\pi}(s')$ $\Leftright..